为了解决 处理器 与 主存储器 之间的速度不匹配问题,引入了高速缓冲存储器 (Cache)。
引入背景 重点
- 矛盾:现代计算机存在“高速 CPU 与低速主存”之间的速度鸿沟。
- 依据:Cache 的有效性基于 程序局部性原理。
物理特性
- 材质工艺:通常采用与 CPU 内部寄存器相同的 SRAM 工艺,访问速度极快。
- 物理位置:由于工艺一致,通常被封装在处理器芯片内部。
Cache 的分级体系
现代处理器通常采用三级 Cache 结构以平衡速度与成本:
- L1 Cache (一级): 访问速度最快,容量最小。通常采用哈佛结构(指令 Cache 与数据 Cache 分离),允许 CPU 同时读取指令和数据以提升性能。
- L2 Cache (二级): 速度略慢,容量稍大。
- L3 Cache (三级): 通常为多核心共享,容量最大。
访存逻辑
CPU 发出主存地址,同时查找 Cache。
-
命中 (Hit): 直接访问 Cache。由于局部性原理,命中率通常非常高。
-
不命中 (Miss): 访问主存,并将数据所在块调入 Cache。
-
性能评估
Cache性能分析
用于评估 Cache 对系统性能的提升程度。
1. 命中率 (Hit Rate, H)
CPU 访存时,在 Cache 中找到所需数据的概率。
- 公式:
- : 访问 Cache 命中的次数。
- : 访问主存的次数(未命中)。
2. 平均访问时间 ()
- 通用公式:
- 一般教科书在讲 Cache 效能时采用此公式。凡是大型考试一律以此为准。 重点
- 蒋本珊教材公式:
- 仅在蒋老师的教科书中使用,反映了先访问 Cache 后访问主存的逻辑差异。
3. 访问效率 ()
- 公式:
- 效率反映了 Cache 带来的加速比。理想情况下 越接近 100% 越好。
- 公式:
-
映射方式
Cache映射方式
映射方式决定了主存块如何放置到 Cache 的行中。
1. 全相联映射 (Fully Associative)
- 规则: 主存中的任意一块可以装入 Cache 中的任意一行。
- 优点: 灵活,块冲突概率最低,Cache 利用率高。
- 缺点:
- 地址变换复杂,需要查阅目录表(或使用昂贵的相联存储器进行并行查找)。
- 查表过程会增加访问延迟,影响 Cache 访问速度。 重点
2. 直接映射 (Direct Mapping)
- 规则: 每个主存块只能映射到 Cache 的固定行中。
- 公式: 。 重点
- 优点: 地址变换速度最快,硬件简单。
- 缺点: 块冲突概率最高,容易出现“抖动”现象。
3. 组相联映射 (Set-Associative)
组相联映射是直接映射与全相联映射的折中方案,是现代计算机最常用的方式。
-
逻辑结构:
- 将 Cache 分成 个组 (Set),每组包含 个行 (Line)。
- 若每组包含 个行,则称为“ 路组相联”(例如图片中每组有 2 行,即为 2 路组相联)。
-
映射规则:
- 组间直接映射: 主存块号按模运算决定其所属的 Cache 组号。
- 组内全相联: 主存块可以存入所属 Cache 组内的任意一行。 重点
-
数学公式:
-
图片逻辑解析:
- 主存分区: 主存被划分为若干个区(如区 0、区 1…),每个区的块数等于 Cache 的组数 。
- 映射关系: 主存每个区中相对位置相同的块,映射到同一个 Cache 组。例如:
- 区 0 的 0 号块、区 1 的 0 号块(全局 4 号块)均映射到 Cache 的 组 set0。
- 进入组内后,该块可以放置在 set0 的第 0 行或第 1 行中的任何一个。
-
特征: “组间直接,组内全相联”。
-
优点:
- 兼顾了直接映射的低成本(查找范围缩小到组内)和全相联的高利用率(组内有多个位置可选)。
- 有效降低了块冲突(抖动)的概率。 重点
指向原始笔记的链接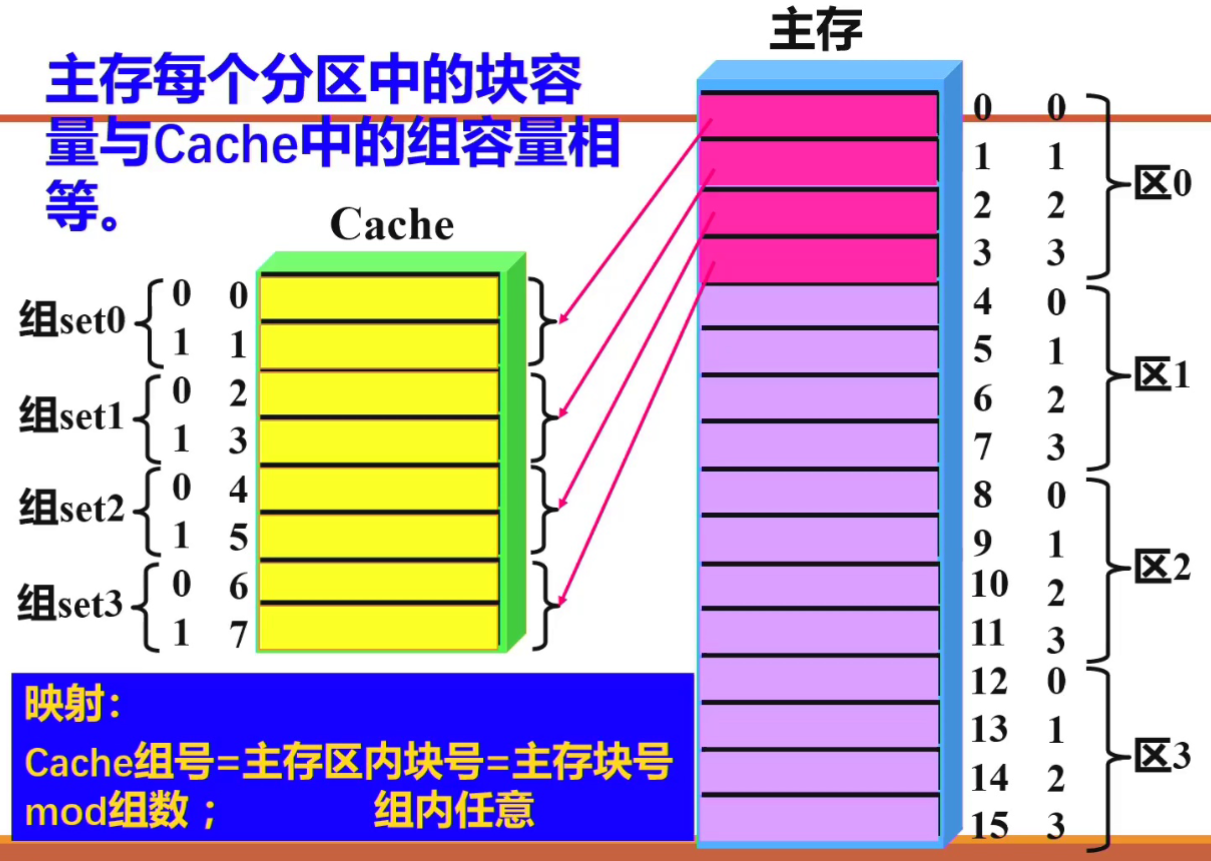
-
一致性策略:
- 写全法 (Write-through): 同时写入 Cache 和主存。
- 写回法 (Write-back): 只写 Cache,仅在块被替换时才写回主存。 重点
Circular transclusion detected: 计算机组成体系原理/Cache映射方式